Экспертная система классификации устройств и процессов на предприятиях ж.д. транспорта
Аннотация
Дата поступления статьи: 08.02.2013В работе рассматривается система, созданная для помощи при организации квалификационного тестирования экспертных групп, а так же в предоставлении программного инструментария для проведения экспертной и автоматизированной кластеризации и классификации приборов и устройств железнодорожной автоматики. Областью применения данного комплекса являются интеллектуальные системы, устройства, и иное оборудование в работе с которым требуется систематическое проведение классификационных измерений. Представлено программное приложение, разработанное на языке программирования высокого уровня Borland Delphi.
Ключевые слова: экспертная система, кластеризация, классификация, приемо-сдаточные испытания, диагностика технического состояния
05.13.18 - Математическое моделирование, численные методы и комплексы программ
На производстве, в работе горки или в ремонтных мастерских регулярно появляются задачи, в которых сотруднику требуется провести оценку и отбор того или иного объекта в зависимости от его свойств. Спектр таких задач весьма широк: от классификации выпускаемой предприятием продукции и отбора приборов и узлов для ремонта подвижного состава до регуляции работы горки при роспуске вагонов. Если в общественной жизни, при решении подобных задач, человек, в основном, полагается на свой жизненный опыт или советы окружающих, то в промышленности, на предприятиях транспорта или при организации перевозочного процесса требуется сотрудничество с квалифицированными экспертами в предметной области, так как риски в случае неверного решения существенно выше. Однако, привлечение экспертов это решение, связанное со значительными материальными и, в некоторых случаях, временными затратами, особенно когда задачи классификации возникают регулярно.
Так эффективность автоматизированных систем, обобщенно называемых автоматизированными системами управления железнодорожным транспортом, в значительной мере зависит от надежного функционирования отдельных подсистем и также от надежности средств железнодорожной автоматики и телемеханики [1]. С другой стороны, анализ процесса движения поездов и действий оперативного персонала отличается от диагностирования отдельного устройства тем, что, как правило, решение о классификации необходимо выдвинуть для каждого нового события удовлетворяющего некоторым условиям, а не для последовательности событий в целом. Подобные алгоритмы удобно реализовывать в подсистеме, построенной на основе хранилища архива событий [2].
Кроме того классификации могут подвергаться интеллектуальные системы, участвующие в организации движения. Некоторые компьютерные системы могут быть «интеллектуальнее» чем остальные. На этот счет Албус (Albus) говорит: «Существуют степени или уровни интеллектуальности, и они определяются следующими критериями: вычислительная мощность системного мозга (или компьютера), сложность алгоритмов, которые система использует для сенсорной обработки, моделирования мира, поведенческой генерации, оценочных суждений и глобальной коммуникации и информация и значения, которые система хранит в своей памяти» [3].
Позднее Мейстель (Meystel) определяет необходимость вектора производительности и интеллектуальности [4, 5]. Это, в свою очередь, означает, что нужна некоторая градация. Но что можно выделить, если взглянуть на измеримые аспекты интеллектуальности? Гудвин (Gudwin) говорит: «От интеллектуальных систем ожидается работоспособность и хорошая работоспособность, в большом наборе различных сред. Свойство интеллектуальности позволяет им максимизировать вероятность успеха, даже если не доступна полная информация о ситуации» [6].
Широкое внедрение информационных технологий, микропроцессорной техники, ПЭВМ на железнодорожном транспорте дает возможность использования аппарата теории распознавания для решения различных задач автоматизации. Следует отметить, что в этом случае не требуется разрабатывать специальные технические устройства, так как использование микропроцессоров позволяет реализовать схему распознавания с помощью соответствующих алгоритмов и программ, т.е. проблема заключается в постановке задачи и разработке соответствующего программного обеспечения [7].
Вместе с тем, уровень развития программных средств сегодня может предоставить требуемый инструментарий для сокращения расходов по данной статье. Так, единожды оплатив услуги экспертной группы и собрав необходимую статистику, можно, используя элементы теорий приемо-сдаточных испытаний и распознавания образов, в дальнейшем проводить классификацию в отдельно взятой задаче автоматизировано.
Из вышеуказанного следует цель для разработки: создание экспертной системы, позволяющей проводить квалифицированную кластеризацию и классификацию процессов и оборудования в рамках задач, возникающих на железнодорожных предприятиях.
На рисунке 1 представлена обобщенная схема работы описываемого программного комплекса.
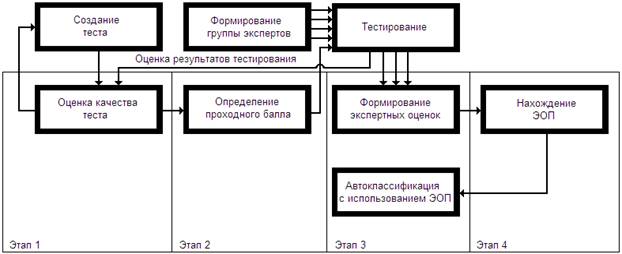
Рис. 1. – Обобщенная схема работы программного комплекса
По ней можно заметить, что начиная с оценки качества теста, предлагаемого группе экспертов и определения проходного балла, работа программы переходит к генерации обучающей последовательности и сравнению результатов экспертной классификации для отбраковки, значительно отличающихся от общей статистики, экспертных решений, а затем к выработке эталонной обучающей последовательности (ЭОП). И, на заключительном этапе, основываясь на полученной последовательности, комплекс предоставляет возможность проводить автоматизированную классификацию.
Ниже подробнее рассматриваются все указанные этапы работы. На каждом из них заполнение и подсчет результатов происходят последовательно, что снижает вероятность случайной ошибки при внесении расчетных данных, а возможность сохранения позволяет использовать уже рассчитанные данные без необходимости повторного вычисления.
Для того чтобы успешно развиваться, организация должна управлять подбором, обучением, оценкой и вознаграждением персонала, т.е. создать, использовать и совершенствовать методы, процедуры, программы организации этих процессов [8]. Чтобы приносить максимальную пользу персонал должен соответствовать определенным требованиям. И только эффективно налаженная система методов подбора и отбора персонала будет способствовать решению этой проблемы [9].
В связи с этим работа начинается с составления теста по конкретной предметной области. Он необходим для аттестации отобранной группы сотрудников и выбора наиболее подготовленных кандидатур на роль экспертов. Данный этап необходим для минимизации риска получения и запоминания системой неквалифицированного мнения, которое впоследствии может повлиять на качество автоматической классификации. Первым шагом во взаимодействии с программным комплексом является оценка данного теста, предлагаемого эксперту или группе экспертов. Для выполнения подобной оценки следует учесть такие параметры, как: структура теста; количество дидактических единиц (ДЕ); вероятность правильного ответа с учетом нечеткости вопроса и случайных ошибок; количество попыток сдачи; предполагаемый уровень знаний аттестуемых сотрудников.
Существенными данными, по результатам оценки теста, можно назвать вероятность правильного ответа по одной дидактической единице, вероятность успешной сдачи при однократном тестировании и окончательную нормируемую вероятность успешной сдачи с учетом количества пересдач [10].
При помощи этой части программы можно получить данные для графиков такого типа как на рисунке 2:
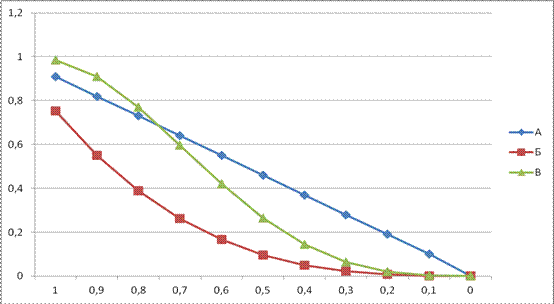
Рис. 2. – Вероятность сдачи при вариации вероятности правильного ответа: а – вероятность правильного ответа по одной ДЕ; б – вероятность сдачи зачета при однократном тестировании; в – окончательная нормируемая вероятность сдачи
Вторым шагом после проверки качества теста является установка проходного балла для конкретного теста. Для этого предлагается рассмотреть процесс квалификационного тестирования как задачу приемо-сдаточных испытаний. В этом случае для решения вопроса об определении границы проходного балла необходимо задаться рядом входных параметров: требуемым от эксперта минимальным уровнем знаний, количеством дидактических единиц, сложностью самого теста, характеризующуюся средней вероятностью угадывания верного ответа, а так же общим количеством вопросов в тесте. Результирующими данными данного расчета являются: вероятность ошибки первого рода – вероятность успешной аттестации эксперта, располагающего знаниями меньшими, чем требуется для решения поставленной задачи; вероятность ошибки второго рода – вероятность не аттестации эксперта, располагающего знаниями, большими требуемых в рамках конкретной задачи; минимально необходимое количество вопросов, на которые тестируемый должен дать верные ответы для соответствия требуемому уровню знаний.
Полученные результаты можно представить в таком виде (таблица 1):
Таблица № 1
Зависимость проходного балла от количества дидактических единиц и уровня знаний при 120 вопросах в тесте и средней вероятности угадывания, равной 0,05
|
|
Количество ДЕ, шт |
||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
||
|
Требуемый уровень знаний, % |
30 |
45 |
25 |
18 |
15 |
12 |
11 |
|
40 |
56 |
31 |
22 |
17 |
15 |
13 |
|
|
50 |
66 |
36 |
26 |
20 |
17 |
15 |
|
|
60 |
77 |
41 |
29 |
23 |
19 |
16 |
|
При данных проходных баллах значения ошибки первого рода (α) будет таким (таблица 2):
Таблица № 2
Значения ошибки первого рода для полученных проходных баллов
|
|
Количество ДЕ, шт |
||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
||
|
Требуемый уровень знаний, % |
30 |
7,5 |
7,7 |
7,9 |
4,5 |
9,1 |
5 |
|
40 |
7,7 |
6,3 |
6,8 |
9,8 |
4,4 |
4,5 |
|
|
50 |
10 |
7,9 |
5 |
7,4 |
5 |
3,1 |
|
|
60 |
8,7 |
8,8 |
6,7 |
4,5 |
4,5 |
6,6 |
|
На втором этапе так же кроме определения границы проходного балла могут быть интересны апостериорные оценки рисков, которые являются наглядным показателем качества предложенного теста. Использование наблюдаемых рисков не меняет принимаемых решений об аттестации, но может существенно изменить представление о достоверности полученных результатов. Для анализа послеопытных оценок рисков следует задаться следующими данными: количество правильных ответов, данное экспертом; общее количество вопросов; верхняя граница, при которой вероятность ошибки первого рода равна 10%; нижняя граница, при которой вероятность ошибки второго рода равна 10%. По результатам такого расчета можно наглядно увидеть динамику поведения вероятностей ошибок первого и второго рода в конкретном тесте.
В алгоритме оценки результатов, для упрощения работы с приложением, все начальные данные кроме количества верных ответов по результату теста вносятся автоматически на основании последнего расчета в части определения проходного балла.
По результатам работы приложения можно наглядно увидеть, при каком количестве правильных ответов ошибка первого рода приближается к нулю. Пример такой интерпретации результатов представлен на рисунке 3. Подобный график выводится в правом верхнем углу соответствующей страницы программного комплекса для наглядного изображения динамики рисков.
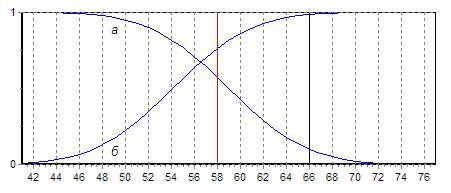
Рис. 3. – Зависимость ошибок от количества правильных ответов при
N = 120, Rн = 58: а – ошибка первого рода; б – ошибка второго рода
После прохождения квалификационного тестирования, экспертам предоставляется перечень оцениваемых элементов и набор параметров, по которым они оцениваются. Такой набор может быть разработан ранее при участии тех же выбранных экспертов, и акцентироваться на наиболее значимых, в данной задаче, признаках. Таким образом, на третьем этапе формируется набор из нескольких идентичных по элементам, но различающихся по классификации обучающих последовательностей.
Позже, на пятом этапе, сформировав эталонную обучающую последовательность, основываясь на внесенных данных, приложение сможет самостоятельно классифицировать новые поступающие элементы. Механизм выведения эталонной обучающей последовательности подробнее описан ниже. Классификация может быть выполнена различными математическими методами, как то: метод эталонов, метод ближайшего соседа, метод Байеса и др. За счет такой гибкости достигается необходимая корректность оценок в зависимости от структуры обучающей последовательности и расчетных данных.
При работе с программой на этом этапе следует обратить внимание на два значимых тезиса.
Во-первых, необходимо искусственно ограничивать обучающую выборку. Так, при бесконтрольном расширении базы знаний, внесенные ранее данные, могут негативно влиять на расчеты. Использование устаревших данных в большинстве случаев будет отрицательно влиять на результат классификации, снижая точность определения.
Во-вторых, так как рассматриваемые параметры интеллектуальности могут иметь разные оценочные шкалы и единицы измерения (или же не обладать таковыми вовсе), в программе проводится бальная оценка. К примеру, эксперты, варьируя свои оценки в диапазоне от 0 до 100, смогут адекватно оценить каждый параметр. В то же время, алгоритмам, обрабатывающим обучающую последовательность не придется сталкиваться с проблемой разных форматов поступающих данных. Исключив данную ситуацию можно значительно повысить точность оценки.
График классов предусмотрен в программе как наглядная демонстрация корректности кластеризации обучающей последовательности и классификации расчетных точек (рис. 4). С его помощью удобно оценивать такие параметры классов как плотность и средний радиус и на их основании контролировать адекватность работы алгоритмов автоматической кластеризации и классификации.
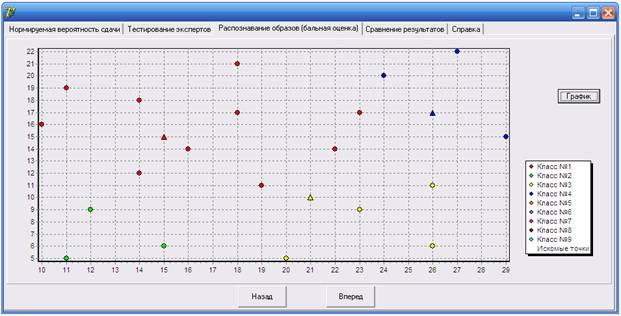
Рис. 4. – График классов
График вызывается нажатием на соответствующую кнопку на форме, которая становится доступна после классификации расчетных точек. Данная функция появляется исключительно при расчете по двум параметрам, т.к. n-мерные пространства при n > 2 не могут быть адекватно отражены программными средствами используемого инструментария.
Масштаб выбирается таким образом, чтобы все расчетные точки и элементы обучающей последовательности были размещены на экране. Классы на графике разделены цветом, точки обучающей последовательности представлены закрашенными кругами, а расчетные точки – треугольниками. Расчетные точки закрашиваются в цвета классов, к которым они были классифицированы, при невозможности однозначно классифицировать расчетную точку на графике она остается не закрашенной, т.е. белым треугольником. Справа от графика показана цветовая схема разделения классов, по которой можно увидеть, что график поддерживает отображение до девяти различных классов.
К четвертому этапу у пользователя данного программного комплекса набирается некоторая статистика по экспертным решениям и возникает необходимость систематизации и объединения этих данных в одну обучающую последовательность, на основании которой, впоследствии, и будет проводиться автоматическая классификация. Для выполнения этих задач в программу был включен рассматриваемый алгоритм. С его помощью ищется «золотая середина» – так называемая эталонная обучающая последовательность. Принцип его работы заключается в следующем: основываясь на нескольких различных классификациях, предоставленных экспертами, программа определяет, к какому классу чаще всего причисляется тот или иной элемент, и создает, таким образом, эталонную классификацию.
Также, в процессе обработки экспертных решений имеет смысл отбраковка тех, что имеют наибольшее расхождение с ЭОП. Если итоговая классификация значительно отличается от какого-то решения эксперта, программа обратит внимание пользователя на данную классификацию и предложит пересчитать ЭОП, устранив решения данного эксперта из рассмотрения. Это обусловлено теми же причинами, что и ограничение длинны ОП на третьем шаге работы программного комплекса, т.е. снижением эффективности определения эталона.
При графическом представлении результатов можно наглядно увидеть, какие из обучающих последовательностей негативно влияют на построение ЭОП (рис 5).
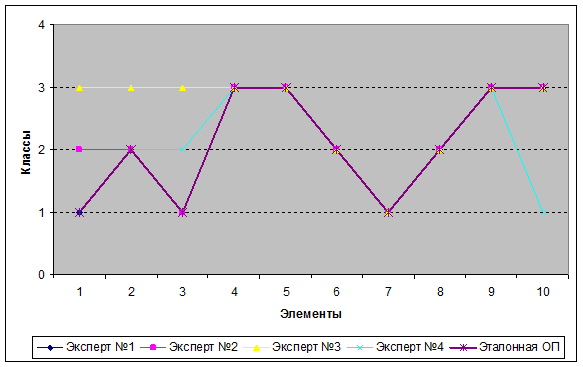
Рис. 5. – Графическое представление работы алгоритма вычисления эталонной обучающей последовательности
Последним этапом, найденная ЭОП может использоваться для проведения автоматической классификации поступающих данных с помощью алгоритма, рассмотренного на третьем шаге.
Вывод: Подобная программная реализация обладает несколькими существенными плюсами. Во-первых, широкий охват предметной области и возможность эффективно работать со спектром различных задач. Это достигается с помощью высокого уровня абстракции и отсутствия привязки к конкретному техническому или производственному процессу. Эта особенность способствует широкому применению рассмотренного программного комплекса для решения практических задач классификации в сфере железнодорожного транспорта. Во-вторых, это точная, математически обоснованная классификация искомых элементов, так как в качестве методов автоматической классификации выбраны известные, проверенные подходы. Это позволяет наглядно оценить и проверить адекватность расчета, тогда как в случае экспертов-людей необходимо будет всецело полагаться на их опыт.
Литература:
- Калинин, Т.С. Спектрально-сигнатурная диагностика микропроцессорных информационно-управляющих систем железнодорожной автоматики и телемеханики [Электронный ресурс] // «Инженерный вестник Дона», 2012, №1. – Режим доступа: http://ivdon.ru/magazine/archive/n1y2012/687 (доступ свободный) – Загл. с экрана. – Яз. рус.
- Прищепа, М.В. Математическое обеспечение распределенной системы диагностирования устройств железнодорожной автоматики и телемеханики [Электронный ресурс] // «Инженерный вестник Дона», 2007, №2. – Режим доступа: http://ivdon.ru/magazine/archive/n2y2007/27 (доступ свободный) – Загл. с экрана. – Яз. рус.
- Albus, J. Outline for a Theory of Intelligence, IEEE Trans. on Systems, Man and Cybernetics, 21(3), May/June 1991, pp.473-509, IEEE.
- Meystel, A. Measuring Performance of Systems with Autonomy: Metrics for Intelligence of Constructed Systems, White Paper for the Workshop on Performance Metrics for Intelligent System, NIST, Maryland, USA, 14-16 August 2000.
- Meystel, A. Performance Metrics for Intelligent Systems, presented at NASA Gaddard’s Information Science and Technology Colloquium Series, 12 March 2003.
- Gudwin, R.R. Evaluating Intelligence: A Computational Semiotics Perspective, 2000 IEEE International Conference on Systems, Man and Cybernetics – SMC2000 – Nashville, Tennessee, USA 8-11 Oct 2000, pp 2080-2085, IEEE.
- Лябах, Н.Н. Техническая кибернетика на железнодорожном транспорте [Текст] / Н. Н. Лябах, А.Н. Шабельников. – Ростов-на-Дону: Изд-во Северо-Кавказского научного центра высшей школы, 2005. – 314 c.
- Карякин А.М. Управление персоналом: Электронное учеб. пособие. 3-я редакция / Иван. гос. энер. ун-т. – Иваново, 2005.
- Побегайлов, О.А. Некоторые аспекты подбора кадров [Электронный ресурс] // «Инженерный вестник Дона», 2012, №4. – Режим доступа: http://ivdon.ru/magazine/archive/n4p1y2012/1121 (доступ свободный) – Загл. с экрана. – Яз. рус.
- Линденбаум, М.Д. Надежность информационных систем [Текст] / М.Д. Линденбаум, Е.М. Ульяницкий; Учебник для вузов ж.-д. транспорта. – М.: ГОУ «Учебно-методический центр по образованию на железнодорожном транспорте», 2007. – 318 с.